Administrative fields
Sometimes it might be needed to have a fixed value that shows from which visit or merger a value originates, this does not only apply to the VIS table but could be applied to all tables. This however does depend on the nature of the database and needs for data management, the field below should be considered an administrative support field for data management.
| VISIT |
| Visit number |
Numeric:
0 = Baseline Visit
1 = First follow up visit
2 = Second follow up visit
etc. |
Often the above field is used for clinical trials databases where there is a need to associate the data directly with a given week’s follow-up. Codes could then be the week number e.g. 4, 12, 24 etc or –1 for screening/randomisation and 0 for baseline visits.
In some cases it might be useful to have a separate field that defines the correct order of the periods. This becomes important where several dates are incomplete (unknown days, unknown months and possibly unknown years). The ordering by date would then not be correct.
One solution to this is use a PERI_ID field that numbers the periods from the 1st until Nth usage:
| PERI_ID |
| Period of usage (1st, 2nd, 3rd etc.) |
| Numeric |
However this is an optional field that for most cohorts may not be needed. It also requires additional maintenance to keep it updated.
For databases that work with double data entry, such as most clinical databases, it becomes necessary to make each data entry unique and backwards traceable. For this to work a field like the above would have to be part of the primary key of each table that requires double data entry.
| ENTRY_ID |
| Number of data entry |
Numeric:
1 = first data entry
2 = second data entry
3 = comparison of 1st and 2nd data entry
4 = final approved record including corrections |
With respect to performance, it might also be a good design to have 3 copies of each table, one to hold the data while being entered and compared, one for the two data entries to be archived into once a final record has been approved and a table holding the final and approved values. This way it is avoided that queries will have to work on checking for ENTRY_ID = 4 and to select amongst a table holding 3 times the almost same data.
As part of an audit trail in a database a time stamp field could be added for each record to fix the exact time when the record last was inserted or updated. Along with the time stamp name of the user who entered or altered data can be recorded.
| T_STAMP |
USER_LOG |
| Date and time of data entry |
Username of user that last inserted or updated data |
| yyyy-mm-dd hh:mm:ss |
character |
Often it's necessary to keep a log of user action in a separate table. The above suggestion will only be valid for inserts and updates, and only be valid for the most recent action performed.
To record a complete audit trail a logging facility must be implemented. In most database management systems this is done using triggers on the tables. For any insert, update or delete actions performed on the data, the user, time stamp, old value and new value are recorded in the logging table.
The T_STAMP field could also include information about which time zone is relevant for data entry. Depending on database requirements this might in fact be mandatory if the FDA’s 21 CRF part 11 on electronic records and signatures applies.
Further normalisation
Depending on performance considerations it might be worth looking at how data are queried for data entry and data analysis. A smaller tblBAS table might increase performance: Since processing a smaller table is always faster than processing a larger table, one could put drop-out, death, birthday, date of aids diagnosis, etc. into separate tables and keep the core patient list in a separate master table
But if the database is used e.g. for BMI calculations directly on the running database, performance might be enhanced by keeping the patient list and the height together in the same table so that a query involves 2 tables (tblBAS and tblVIS) rather than perhaps 3 or more.
Another consideration is space. Although it may not be much of an issue, it will be possible to minimise the actual size of the database by putting fields that may be empty for most patients, like death information, into a separate table in a 0-1 to 1 relation to the master table.
Lookup tables
In a running database the #_ID fields could be implemented as a foreign key to a linked lookup table containing all possible codes and their corresponding definitions in a text string.
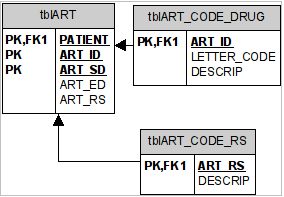
This setup not only enables integrity of the data, but also defines the domain1 for the #_ID values and enables data to both become human readable and easily recoded2.
An important note on lookup tables is that the performance on a large database can be slowed significantly by using character based keys to link lookup tables with the primary table as it is presented in this document. A work around is to use numeric value for the codes.
1: Domain is a term in the definition of the relational database model that defines a set of allowed values for a given set of fields (attributes), the mixing of different domains is not allowed in order to preserve the integrity of a relational and normalised model.
2: Easily recoded permanently if the relation is specified as cascade on update or recoded dynamic by selecting a different column from the lookup table when querying the data through SQL
Performance
As already outlined in the above section, there are also performance issues that may have to be considered.
When using the suggested data types presented in this document for a database implementation, it may be worth looking at the actual data at hand when defining the final data types. The aim of this document is to present a format that will work between cohorts with rather different setups.
If it is at all possible in many cases there may be a large performance gain by using numeric instead of character fields. Character fields have been suggested here for, amongst others, the PATIENT field. If the PATIENT id is purely numeric it’s worth using a numeric data type since it always faster for querying than a character field.
Whenever the field has to be character, make sure that only the needed amount of space is assigned for the field length; there is no need to assign 50 characters of memory if the field in fact only stores a 3-letter code.